
Solution Hautement Disponible
| Présentation et définition du projet
Ce projet a été réalisé dans le cadre du projet fil rouge lors de mon alternance « Administrateur Système DevOps » à DevUniversity. Je devais réaliser un projet de déploiement d’une solution de façon automatisée dans le Cloud. Pour cela, il a été décidé en entreprise que je réalise un POC de déploiement de la solution de monitoring interne (Prometheus, Grafana) dans le cloud Azure.
Dans l’équipe, ce projet est vu comme une première approche dans le Cloud qui permettrait d’explorer les fonctionnalités et d’autres outils DevOps.
| Objectifs et Contexte
Le but de ce projet était d’utiliser des outils comme Terraform, Helm et GitHub Actions afin de proposer une solution hautement disponible et déployable automatiquement. L’objectif était aussi d’expérimenter les différentes fonctionnalités d’un service Kubernetes managé dans le Cloud, notamment au niveau des différents types de scalabilité disponibles via ce service.
La réalisation de ce projet sur le cloud Azure a dû être réalisée via un compte Microsoft obtenu lors d’une formation Azure effectuée en entreprise. Ce compte m’a été fourni via la société externe ayant réalisé la formation. Le compte fourni lors de ma formation contenait 100$ de crédits Azure, ce qui m’a permis de réaliser ce projet.
| Enjeux
L’enjeu de ce POC était de déployer une solution de monitoring hautement disponible dans un environnement Cloud afin de mettre en évidence et de dresser un comparatif entre deux orchestrateurs (AKS versus Podman-compose), hébergement local versus Cloud ou encore SVN versus GitHub.
Ce projet pourrait être un point de départ concernant la future migration des autres applications web de mon équipe dans le cloud Azure.
| Risque
Le principal risque de ce projet était en lien avec le compte Azure fourni par l’organisme de formation.
En effet, malgré le fait que celui-ci soit crédité de 100$, j’aurais potentiellement été bloqué dans l’avancement de mon projet si je dépassais la limite du budget disponible. Le cloud Azure est assez récent dans l’entreprise et les services AKS sont pour l’instant priorisés aux équipes infra/IT. Ainsi, l’accès aux différents services en entreprise n’avait pas été possible.
| Etapes du projet
Terraform : mise en place de cluster AKS
J’ai créé un dépôt GitHub afin de pouvoir créer le code permettant le déploiement de l’infrastructure AKS. J’ai nommé le dépôt « monitoring-AKS-infra-cluster», et j’ai créé une arborescence permettant d’utiliser Terraform comme outil de déploiement.
Figure: Répertoire GitHub « monitoring-AKS-infra-cluster »
Le fichier main.tf définit les ressources et les configurations nécessaires pour créer un cluster AKS sur Azure (cf. annexe).
Premièrement, je spécifie la ressource « azurerm_resource_group » pour la mise en place d’un groupe de ressources où je fais déployer l’architecture (ici monitoring).
Dans un second temps, la ressource « azurerm _container_registry » permet le déploiement du registre de conteneurs qui va servir à héberger les images qui vont être déployées ensuite dans le cadre du déploiement applicatif.
Enfin, je spécifie la ressource « azurerm_kubernetes_cluster » « aks » pour la mise en place du cluster avec la configuration du pool de noeuds. J’utilise dans ce déploiement un module officiel de hashicorp : « hashicorp/azurerm ». Les fichiers variables.tf et terraform.tfvars permettent de définir et déclarer les variables essentielles au fichier main.tf (région azure, nom du cluster, nom du groupe de ressource et nom du registre de conteneurs).
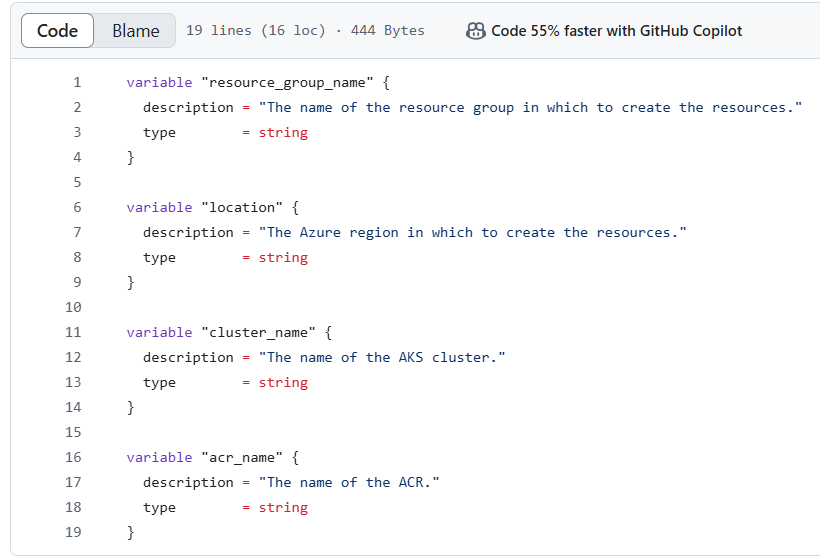
Figure: Fichier variables.tf
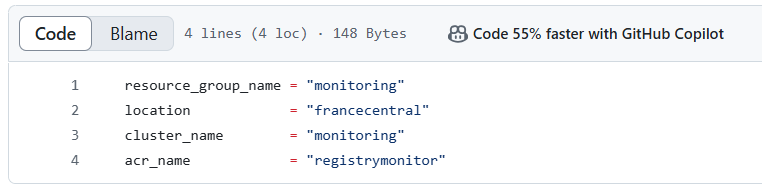
Figure: terraform.tfvars
Helm : mise en place des micro-services
Après avoir créé un dépôt permettant de mettre en place un cluster AKS azure, j’ai mis en place un dépôt permettant cette fois de déployer les services applicatifs sur le cluster.
Figure: Répertoire GitHub « monitoring-AKS-app-helm »
Ainsi, j’ai nommé le dépôt « monitoring-infra-app-helm », et j’ai créé une arborescence permettant le déploiement de ma solution de monitoring à l’aide de l’outil Helm. Ce répertoire est un fork du répertoire GitHub prometheus-community/helm-charts/kube-prometheus-stack. Les dossiers charts et templates contiennent les fichiers Helm qui vont servir à déployer les différents micro-services.
Figure: Dossier charts
Le chart crds (Custom Resource Definition) permet de définir et gérer les configurations de Prometheus, ce qui permet une gestion déclarative et automatisée des instances Prometheus. Ces ressources sont ensuite utilisées par le service prometheus-operator. Cet opérateur automatise la création, la mise à jour et la suppression des instances Prometheus et des composants associés. Il peut aussi faciliter la gestion de plusieurs instances Prometheus dans un cluster Kubernetes. Enfin, l’opérateur s’intègre étroitement avec Kubernetes, utilisant des concepts comme les ServiceMonitors, PodMonitors, et AlertmanagerConfigs pour gérer les configurations de surveillance.
Le fichier values.yaml à la racine du projet contient une multitude d’options et de configurations qui permettent de personnaliser le déploiement de Prometheus et de ses composants associés (spécificités des pods, réplicas, services, ..).
Le service AKS nous permet d’optimiser la disponibilité et la scalabilité à plusieurs niveaux de la solution de monitoring. Par exemple, j’ai pu mettre en place un scaling vertical à l’aide de Vertical Pod Autoscaling (VPA) au niveau des différents pods de la solution. Pour réaliser cela, j’ai créé un nouveau fichier template (format yaml) ainsi qu’un fichier crd que j’ai importés depuis le dépôt officiel de Kubernetes : github.com/kubernetes/autoscaler/blob/master/vertical-pod-autoscaler/deploy/vpa-v1-crd-gen.yaml
J’ai dû aussi gérer le cas d’attacher dynamiquement le VPA aux pods prometheus en fonction de l’environnement (staging, qa, production). Ce mécanisme est géré dans le fichier yaml VPA.
Concernant le scaling horizontal, celui-ci est plus difficile à mettre en place dans le cadre de cette solution de monitoring. En effet, la réplication d’un pod en cas de défaillance ou de montée en charge n’est pas possible via le Horizontal Pod Autoscaling (HPA) car Prometheus collecte des informations à des endpoints définis et une exécution simultanée de micro-services identiques engendrerait des conflits.
Cependant, un scaling horizontal est possible en utilisant Thanos qui permet de gérer ce besoin. Thanos permet de distribuer les données de métriques entre plusieurs instances de Prometheus. Il assure la redirection vers des instances prometheus disponibles et permet aussi d’associer un service Azure comme Azure Blob Storage pour une très grande rétention de données.
Mes connaissances en « Cloud Computing » m’ont permis de travailler efficacement sur ce projet.
GitHub Actions : CI/CD
J’ai mis en place une automatisation de déploiement à l’aide de GitHub Actions. En effet, j’ai rédigé un fichier worflow pour chaque dépôt (infra AKS, app Helm). Le worflow du dépôt infra permet de redéployer le cluster AKS lorsqu’on modifie un fichier Terraform et qu’on commit dans la branche ‘main’. Lorsque le cluster AKS est re-déployé avec succès, le worflow déclenche via l’API GitHub le workflow du dépôt applicatif. La requête est sécurisée via un token GitHub.
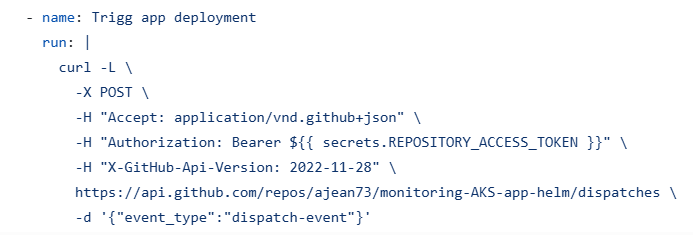
Ainsi, dès qu’une modification est effectuée dans le cluster AKS, l’application est directement redéployée à son tour. Le worflow du dépôt applicatif permet de déployer l’application dans trois environnements AKS différents (staging, qa, production). Le principe est de déployer d’abord en staging, de tester que les pods et services sont tous dans des états de fonctionnement. Si c’est le cas alors le déploiement s’effectue dans l’environnement qa puis de la même façon jusqu’à l’environnement de production. L’avantage de l’utilisation des espaces de noms du service AKS est de pouvoir avoir sur le même cluster, mais séparé de façon cloisonnée, une version identique sur chaque environnement.
Ce projet a renforcé mes compétences en « CI/CD » avec l’utilisation d’un nouvel outil : GitHub Actions.
| Les acteurs
J’ai dû réaliser ce projet en autonomie, car il n’y a pas d’expertise sur le Cloud au sein de l’équipe. De plus, lorsque j’ai réalisé ce projet le Cloud Azure était un peu utilisé dans l’entreprise mais pas dans mon équipe.
J’ai néanmoins réalisé des points hebdomadaires avec mon tuteur qui s’assurait du bon déroulement du projet.
| Les résultats
J’ai utilisé dans cette solution des dépôts GitHub pour le versionnement du code applicatif. Le service AKS m’a permis d’orchestrer les micro-services d’images stockées dans un registre de conteneur (service Azure).
Dans cette solution, toute la partie déploiement a été automatisée à l’aide de GitHub Actions qui font appel aux outils Terraform pour l’infrastructure et Helm pour l’applicatif.
Le POC de migration de solution de monitoring sur un cluster AKS Azure a permis de mettre en évidence et de dresser un comparatif entre deux orchestrateurs, hébergement local versus Cloud ou encore SVN versus GitHub. On remarque de nombreux avantages pour la solution hébergée dans le Cloud Azure.
En effet, l’orchestrateur AKS offre de nombreuses fonctionnalités que l’on ne retrouve pas à travers un outil comme podman-compose. La solution dans le cloud Azure est plus résiliente, disponible et facilement évoluable. Une architecture AKS permettrait de répartir les applications en plusieurs micro-services et de pouvoir gérer la scalabilité à plusieurs échelles. Cela a permis de me rendre compte que le Cloud peut offrir un environnement propice à des applications hautement disponibles.
Un autre avantage est les espaces de noms AKS qui permettent d’avoir la même version applicative dans des environnements séparés.
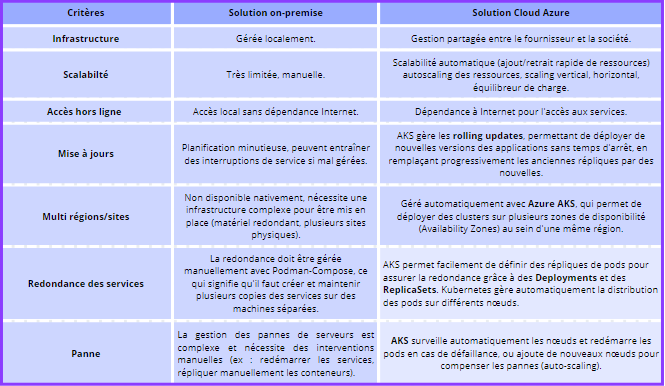
Tableau comparatif de la solution on-premise VS Cloud Azure
| Les lendemains du projet
J’ai présenté le POC et le comparatif au management. Une future modernisation de l’architecture des applications web va avoir lieu et j’espère que ce travail aidera à choisir les meilleurs solutions techniques.
Je serais intéressé d’avoir l’opportunité de pouvoir contribuer aux différents projets de modernisation des applications web.
| Mon regard critique
Ce projet m’a permis d’avoir une vision plus large des outils DevOps en manipulant par exemple GitHub Actions pour la CI/CD. Pour la gestion du code j’ai travaillé avec les outils SVN et GitHub.
Je pense que l’équipe pour laquelle j’ai réalisé ce POC observerait de nombreux avantages de migrer certaines de ses applications complexes vers une solution Kubernetes. Cependant, mon équipe possède aussi certaines applications web assez légères et simples. Dans ce cas, un orchestrateur comme podman-compose serait suffisant.
Un autre point à prendre en considération, la mise en place et la compréhension d’un service comme Azure Kubernetes Service (AKS) sont complexes et demandent une expertise technique avancée. Cette tâche représente une charge de travail considérable, impliquant des étapes telles que la configuration initiale, la gestion des clusters, l’intégration continue et le déploiement continu, ainsi que la surveillance et la maintenance des services déployés.
En somme, je trouve que le point le plus important est de s’assurer d’adapter la solution au besoin et de ne pas ajouter de complexité quand ce n’est pas nécessaire.